Keep all the necessary information in one file
Scraping Camel is developed by Shopitak, which focuses on developing applications for the Mergado ecosystem. The app goes through the HTML pages of the website and obtains any information from them. The app saves it and generates one output CSV file. Thanks to this, the app is suitable for high-quality data analysis of products and categories.

What data can you get from the site? Using the app, you will receive any information from the website, such as Title, Meta Description, headings H1 and H2, Google Analytics tag ID, or Google Tag Manager.
The application can also process websites that are not online stores. These are, for example, various catalogs (fashion, travel tickets, etc.) or web presentations. It can edit the data in Mergado for PPC advertising on Google Ads, and it can further process the usual store procedures. If the user’s shop system does not generate XML (or other) feeds, it can obtain the necessary information and further work with them in Mergado.
With Scraping Camel, you apply feed marketing workflows from online stores with an XML feed to websites without a cart. Data is continuously automated. Outputs are available online for other applications or data connections.

Download the entire site into one CSV
Download the ENTIRE WEB to one CSV. Scraping Camel will do it for you and will keep the CSV content updated with new information as you change the site.
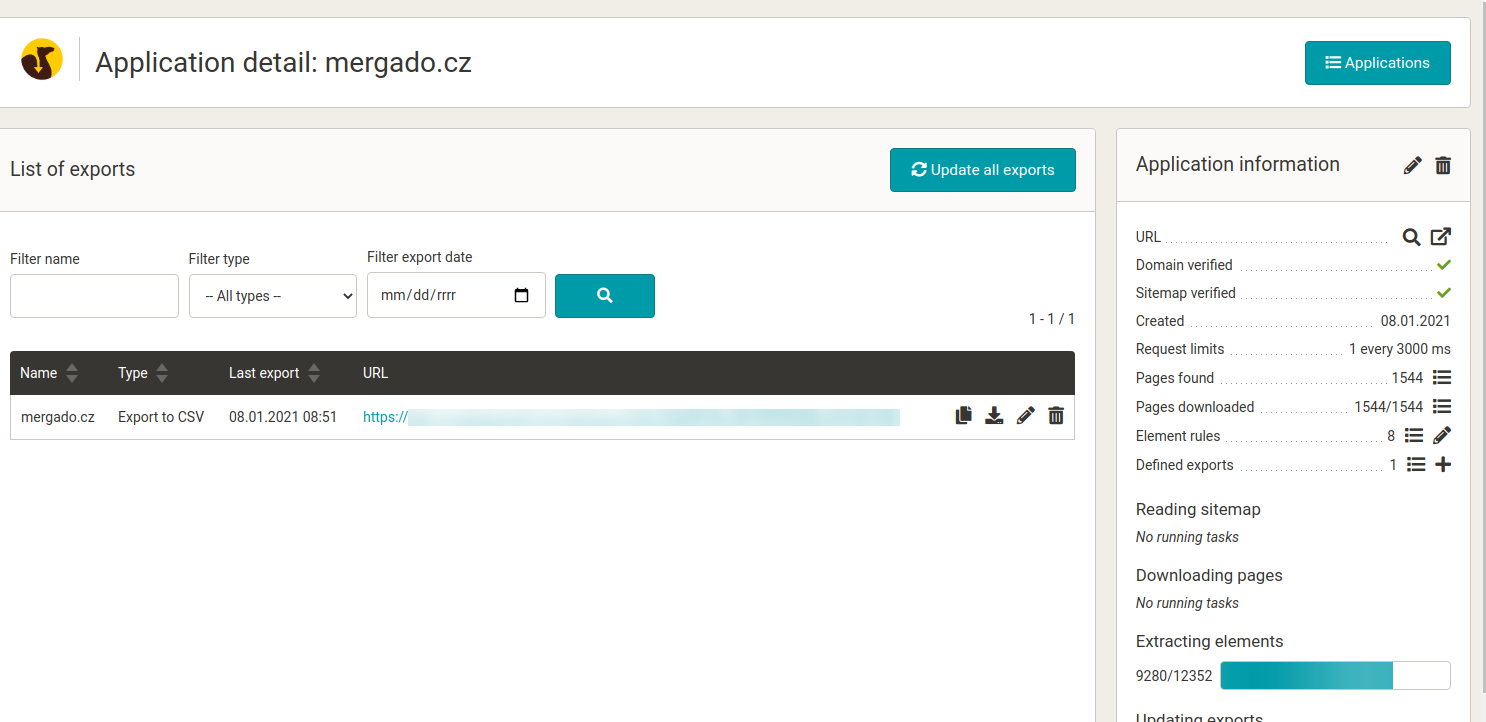
How to use Scraping Camel?
At the testing store, we will show you how easy it is to get SEO data and a product description.
Scraping Camel regularly and automatically checks the destination site. If it finds a new page, it will process it immediately and project any changes in the output CSV file.
The app can be used not only by online store operators. Marketers, specialists in SEO or PPC advertising can also load product data or services from a page without a feed into the CSV file.
What are the differences between the application and other tools? Programs such as Screaming Frog or Xenu work on a one-time basis and run on a local device. Scraping Camel works the opposite — it runs on a non-stop server. It provides outputs in machine-readable form, which you can further process. You may use it for one-time analyzes, where the data is automatically processed by other software.
Summary
Benefits of Scraping Camel:
- continuous monitoring of changes
- works on the server (non-stop)
- possibility to upload to Mergado as an input file for export and work with it in the usual way
- unlimited number of sites per account
What you should know:
- the app does not render JavaScript, it only works on HTML
- the principle of data extraction is based on characters, not on elements
- the condition for using Scraping Camel is a functional sitemap file and a verified domain
Try the Scraping Camel features for 30 free days and gain the benefits of quality data.